
做的比較好的手機網(wǎng)站崇州市城鄉(xiāng)建設局網(wǎng)站
鶴壁市浩天電氣有限公司
2026/01/24 08:24:01
做的比較好的手機網(wǎng)站,崇州市城鄉(xiāng)建設局網(wǎng)站,網(wǎng)站建設單選題,長沙廣告設計公司排名目錄
一、認識數(shù)組
1、數(shù)組的概念
2、數(shù)組的類型
3、數(shù)組在JVM是如何存儲
二、一維數(shù)組
1、一維數(shù)組的定義
1、動態(tài)初始化#xff1a;
2、靜態(tài)初始化#xff1a;
2、一維數(shù)組的使用 [1、數(shù)組中元素的使用](about:blank#%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%…目錄一、認識數(shù)組1、數(shù)組的概念2、數(shù)組的類型3、數(shù)組在JVM是如何存儲二、一維數(shù)組1、一維數(shù)組的定義1、動態(tài)初始化2、靜態(tài)初始化2、一維數(shù)組的使用[1、數(shù)組中元素的使用](about:blank#%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A01%E3%80%81%E6%95%B0%E7%BB%84%E4%B8%AD%E5%85%83%E7%B4%A0%E7%9A%84%E4%BD%BF%E7%94%A8) [1、通過下標使用](about:blank#%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A01%E3%80%81%E9%80%9A%E8%BF%87%E4%B8%8B%E6%A0%87%E4%BD%BF%E7%94%A8) [2、遍歷快速訪問數(shù)組中的每一個元素](about:blank#%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A0%C2%A02%E3%80%81%E9%81%8D%E5%8E%86%E5%BF%AB%E9%80%9F%E8%AE%BF%E9%97%AE%E6%95%B0%E7%BB%84%E4%B8%AD%E7%9A%84%E6%AF%8F%E4%B8%80%E4%B8%AA%E5%85%83%E7%B4%A0) [1、通過循環(huán)實現(xiàn)遍歷訪問每一位元素打印了數(shù)組中的每一個元素](about:blank#%C2%A0%20%C2%A0%20%C2%A0%20%C2%A0%201%E3%80%81%E9%80%9A%E8%BF%87%E5%BE%AA%E7%8E%AF%E5%AE%9E%E7%8E%B0%E9%81%8D%E5%8E%86%E8%AE%BF%E9%97%AE%E6%AF%8F%E4%B8%80%E4%BD%8D%E5%85%83%E7%B4%A0%EF%BC%88%E6%89%93%E5%8D%B0%E4%BA%86%E6%95%B0%E7%BB%84%E4%B8%AD%E7%9A%84%E6%AF%8F%E4%B8%80%E4%B8%AA%E5%85%83%E7%B4%A0%EF%BC%89%EF%BC%9A) [2、直接使用Java中遍歷數(shù)組的工具](about:blank#%C2%A0%20%C2%A0%20%C2%A0%20%C2%A0%202%E3%80%81%E7%9B%B4%E6%8E%A5%E4%BD%BF%E7%94%A8Java%E4%B8%AD%E9%81%8D%E5%8E%86%E6%95%B0%E7%BB%84%E7%9A%84%E5%B7%A5%E5%85%B7)2、數(shù)組的運用場景1、保存數(shù)據(jù)2、作為函數(shù)的參數(shù)3、作為函數(shù)的返回值三、二維數(shù)組1、二維數(shù)組的定義1、普通二維數(shù)組的定義2、不規(guī)則二維數(shù)組的定義2、二維數(shù)組中的使用1、二維數(shù)組中元素的使用2、二維數(shù)組遍歷元素中的每一位四、Arrays中的常用的方法1、數(shù)組轉(zhuǎn)字符串1、自定義實現(xiàn)to String方法2、直接使用Arrays中的to String方法2、拷貝拷貝數(shù)組時也可以實現(xiàn)擴容1、Arrays中的copyOf方法2、Arrays中的copyOfRange方法3、System.arraycopy方法3、查找1、遍歷查找2、二分查找二分查找只能在順序排序的數(shù)組中使用1、自定義實現(xiàn)二分查找2、使用Arrays中的二分查找4、排序1、自定義實現(xiàn)冒泡排序功能2、使用Arrays中的sort()方法實現(xiàn)排序3、實現(xiàn)逆序排序一、認識數(shù)組1、數(shù)組的概念假設現(xiàn)在你要將一個班的成績?nèi)窟M行儲存此時若一個一個定義double score190.5; double score294.12; double score387.56; double score494.5; double score588.75; //……此時可以看出一個一個定義過于復雜而且這一組數(shù)的數(shù)據(jù)類型都是一樣的此時就可以通過數(shù)組來進行定義這一組數(shù)據(jù)double [] scores{90.5,94.12,87.56,94.5,88.75};用數(shù)據(jù)便于定義數(shù)據(jù)類型都一致的大量數(shù)據(jù)數(shù)組的定義數(shù)組可以看作是相同類型元素的一個集合在定義大量數(shù)據(jù)類型一致的數(shù)據(jù)時可以使用數(shù)組進行定義2、數(shù)組的類型數(shù)組變量是引用類型數(shù)據(jù)數(shù)組變量儲存的是第一個數(shù)組元素在堆上的地址實際上就是一個16進制的數(shù)字3、數(shù)組在JVM是如何存儲數(shù)組變量是存儲在棧中的一個十六進制的一個數(shù)字這個數(shù)字是數(shù)組元素中第一個元素的地址數(shù)組名和數(shù)組元素的關系如下圖所示二、一維數(shù)組1、一維數(shù)組的定義1、動態(tài)初始化先表明在內(nèi)存空間中存儲的元素個數(shù)先開辟一部分空間再對這部分的空間進行使用開辟空間的大小由數(shù)組中存儲的元素個數(shù)和定義的數(shù)組是什么元素類型所共同決定的int [] arraynew int[5];//表明在內(nèi)存空間中申請了一個長度為5的空間20個字節(jié) String [] array1 new String[3]; //一個可以容納三個字符串的數(shù)組2、靜態(tài)初始化在為這個數(shù)組開辟空間的同時對其中的空間進行賦值int [] array{1,2,3,4,5,6}; //或者是int [] arraynew int[]{1,2,3,4,5,6}; //注在生成數(shù)組對應的空間時如果對其進行了賦值則不能在等號右端指定元素的個數(shù) //電腦會自動查詢元素個數(shù) String[] arrayhello;2、一維數(shù)組的使用1、數(shù)組中元素的使用1、通過下標使用數(shù)組中的元素在堆中的存儲空間是連續(xù)的此時若要訪問數(shù)組中的某一個元素可以通過下標進行訪問數(shù)組中的元素對應的下標都是從0開始的如上圖中使用的scores數(shù)組對應的下標此時可以通過下標訪問數(shù)組中的每一個元素對其進行更改或者賦值等操作如scores[0]96.5;//將數(shù)組中為0下標的元素賦值更改成了96.5 System.out.println(scores[0]);//打印了數(shù)組中下標為0的元素 //……2、遍歷快速訪問數(shù)組中的每一個元素遍歷數(shù)組——即對數(shù)組中的每一位元素進行某種操作例如打印等1、通過循環(huán)實現(xiàn)遍歷訪問每一位元素打印了數(shù)組中的每一個元素int[] scoresnew int[]{1,2,3,4,5,}; int lenarr.length;//可以運用數(shù)組名.lence的形式計算數(shù)組長度類似于C語言中的strlen,計算其中的元素個數(shù) System.out.println(數(shù)組的長度len); for (int i 0; i len; i) { System.out.print(arr[i] ); }2、直接使用Java中遍歷數(shù)組的工具int []arrnew int[]{1,2,3,4,5,}; //這個循環(huán)遍歷數(shù)組將數(shù)組中的每一個元素都放到y(tǒng)中去 for (int y:arr){ System.out.print(y ); }注意數(shù)組元素的訪問不能超過數(shù)組的訪問界限即有n個元素則只能訪問到以n-1為下標的元素否則編譯器會報下標越界異常ArrayIndexOutOfBoundsException2、數(shù)組的運用場景1、保存數(shù)據(jù)數(shù)組在Java中可以用于保存數(shù)據(jù)類型一樣的大量數(shù)據(jù)例如上述的用于保存一個班的成績double [] scores{90.5,94.12,87.56,94.5,88.75};2、作為函數(shù)的參數(shù)在Java中數(shù)組也可以作為函數(shù)的參數(shù)進行傳遞本質(zhì)上是對數(shù)組中首元素的地址進行傳遞例如寫一個arrayPrint方法實現(xiàn)打印數(shù)組中的所有元素的功能public static void arrayPrint(int[] arr){ for (int i 0; i arr.length; i) { System.out.println(arr[i]); } } public static void main(String[] args) { int[] arraynew int[]{1,2,3,4,5}; arrayPrint(array);//數(shù)組傳參是傳的是堆中存放元素的地址 //但在本質(zhì)上還是傳的數(shù)組中所指向的對象數(shù)組中的元素 }注也可以使用上述的遍歷的方法實現(xiàn)打印public static void arrayPrint(int[] arr){ for (int i arr) { System.out.println(i ); } } public static void main(String[] args) { int[] arraynew int[]{1,2,3,4,5}; arrayPrint(array);//數(shù)組傳參是傳的是堆中存放元素的地址但在本質(zhì)上還是傳的數(shù)組中所指向的對象數(shù)組中的元素 }3、作為函數(shù)的返回值在Java中可以直接將一個數(shù)組作為函數(shù)的返回值//返回一個數(shù)組,在C語言中不能返回多個數(shù)但在Java中可以通過返回一個數(shù)組來返回多個返回值 public static int[] fun1(){ int a10; int b20; int[] arrnew int[]{a,b}; return arr; } public static void main(String[] args) { int[] arrfun1(); String s Arrays.toString(arr); System.out.println(s); }三、二維數(shù)組1、二維數(shù)組的定義1、普通二維數(shù)組的定義普通二維數(shù)組的定義方法和一維數(shù)組的類似也有動態(tài)初始化和靜態(tài)初始化也可以在定義時直接賦值2//二維數(shù)組定義 public static void main(String[] args) { int[][] array{{1,2,3},{4,5,6}}; // 行列 int[][] array1new int[2][3]; int[][] array2new int[][]{{1,2,3},{4,5,6}}; System.out.println(array); System.out.println(array.length); // array存放的是地址地址指向的是兩個一維數(shù)組的地址 System.out.println(array[0]); System.out.println(array[0].length); //System.out.println(Arrays.toString(array[0])); }注1、二維數(shù)組中可以通過行和列來理解例如上述舉例的array1中int[2][3]表示定義了一個兩行三列的數(shù)組一共是6個整數(shù)儲存在這個數(shù)組中2、二維數(shù)組的本質(zhì)也是一維數(shù)組只不過每一個二維數(shù)組的元素都算作是一個一維數(shù)組例如定義了一個二維數(shù)組array1其中存儲了兩行三列的數(shù)據(jù){123}{456}舉例中的地址是隨便編的實際地址格式并不是這樣的2、數(shù)組名.length 可以用來計算數(shù)組的行數(shù)例如array.length計算的是數(shù)組名為array的數(shù)組的行數(shù)public static void main(String[] args) { int[][] array{{1,2,3},{4,5,6}}; System.out.println(array.length); }例如上述代碼定義了一個兩行三列的數(shù)組其array.length打印出來的結果是23、數(shù)組名[a].length 假設定義了一個m行n列的數(shù)組則計算列數(shù)時,a可以取從0到m-1的任意整數(shù)值 可以用來計算二維數(shù)組的列數(shù)2、不規(guī)則二維數(shù)組的定義不規(guī)則二維數(shù)組指的是那些沒有在定義時沒有確定列的二維數(shù)組可以理解為可以確定一個二維數(shù)組中有多少個一維數(shù)組但是每一個一維數(shù)組中的元素個數(shù)可以不同或者說不知道是多少例如//不規(guī)則二維數(shù)組的定義 //二維數(shù)組在定義時可以省略列但是不能省略行與C語言恰好相反 public static void main13(String[] args) { int[][] arraynew int[2][]; array[0]new int[3]; array[1]new int[5]; //定義了一個兩行的不規(guī)則數(shù)組第一行有3列第二行有5列 }注不規(guī)則二維數(shù)組定義時只能省略數(shù)組的列不能省略數(shù)組的行與C語言的恰好是相反的且要定義不規(guī)則的二維數(shù)組只能是先定義一個二維數(shù)組中所包含的一維數(shù)組的個數(shù)然后再分別規(guī)定一維數(shù)組中的元素個數(shù)例如一個兩行第一行三列第二行五列的二維數(shù)組的空間分布2、二維數(shù)組中的使用1、二維數(shù)組中元素的使用二維數(shù)組中元素的使用和一維數(shù)組類似都是通過下標進行訪問數(shù)組中的元素的值public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; System.out.println(array1[1][4]); System.out.println(array1[0][2]); }特別注意在對不規(guī)則的二維數(shù)組進行訪問其中的元素時一定要特別注意不要越界訪問如不關注每一行的列數(shù)然后直接進行訪問可能就會導致越界訪問錯誤public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; System.out.println(array1[1][4]); System.out.println(array1[0][4]); }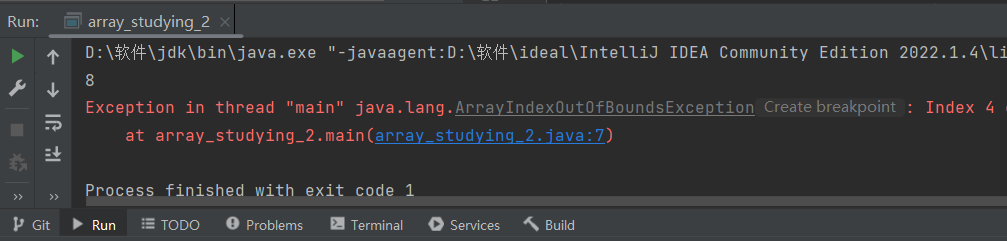此處的第二個打印是打印第一行中的第五列的元素但是第一行中只有三列此時進行訪問第五列就會出現(xiàn)越界訪問的錯誤2、二維數(shù)組遍歷元素中的每一位1、使用雙循環(huán)法遍歷數(shù)組中的每一位注第一層循環(huán)是指的是二維數(shù)組的行數(shù)第二層循環(huán)是指的是二維數(shù)組的列數(shù)public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; for (int j 0; j array1.length; j) { //循環(huán)行 for (int i 0; i array1[j].length; i) { //循環(huán)列 System.out.print(array1[j][i] ); } System.out.println(); } }注不能直接使用一層循環(huán)打印二維數(shù)組中的元素因為二維數(shù)組中的元素是地址一維數(shù)組中首個元素的地址2、使用循環(huán)法加Java中的遍歷工具注在第一層的循環(huán)仍然是二維數(shù)組的行數(shù)第二層的for each循環(huán)是打印的存在二維數(shù)組中一維數(shù)組中的元素public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; for (int i 0; i array1.length; i) { //行數(shù) for (int y:array1[i]) { System.out.print(y ); } System.out.println(); } }注同樣不能直接使用for each循環(huán)來遍歷二維數(shù)組如public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; for (int[] y:array1) { System.out.println(y); } }不然會直接遍歷二維數(shù)組中的元素而二維數(shù)組中的元素是一維數(shù)組即是一維數(shù)組中首個元素的地址四、Arrays中的常用的方法1、數(shù)組轉(zhuǎn)字符串1、自定義實現(xiàn)to String方法1、一維數(shù)組可以通過訪問一維數(shù)組的下標遍歷打印一維數(shù)組從而實現(xiàn)和to String類似的效果如使用for循環(huán)實現(xiàn)打印一個一維數(shù)組arrays1中的元素仿造to String方法的效果public static void main(String[] args) { int[] array1new int[]{4,5,6,7,8}; System.out.print([); for (int i 0; i array1.length-1; i) { System.out.print(array1[i], ); } System.out.print(array1[array1.length-1]); System.out.println(]); }2、二維數(shù)組同理二維數(shù)組也可以通過訪問下標的方法實現(xiàn)和to String類似的效果public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; System.out.print([); for (int i 0; i array1.length; i) { //行 System.out.print([); for (int j 0; j array1[i].length-1; j) { System.out.print(array1[i][j], ); } System.out.print(array1[i][array1[i].length-1]); System.out.print(]); } System.out.println(]); }注實現(xiàn)遍歷時注意最后一個元素的打印不同之前的格式之前的元素打印都是打印完這個元素之后再在其后加一個逗號和一個空格2、直接使用Arrays中的to String方法1、一維數(shù)組在Arrays包中會有將數(shù)組直接轉(zhuǎn)化為字符串的方法可以使用Arrays中的方法直接將數(shù)組轉(zhuǎn)化為字符串注意但是在使用Arrays中的方法前需要導入Arrays包在代碼的最前方寫上import java.util.Arrays;如圖public static void main(String[] args) { int[] arraynew int[]{1,2,3,4,5,6}; System.out.println(Arrays.toString(array)); }2、二維數(shù)組二維數(shù)組中存的是一維數(shù)組的數(shù)組名而一維數(shù)組名表示的是一維數(shù)組首個元素的地址二維數(shù)組本質(zhì)上存的是地址所以不能直接使用不然to String方法會將二維數(shù)組中的元素變成變成字符串將那些地址變成字符串如public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; System.out.println(Arrays.toString(array1)); }此時需要深度to String在toString方法前加上一個deep如public static void main(String[] args) { int[][] array1new int[][]{{1,2,3},{4,5,6,7,8}}; System.out.println(Arrays.deepToString(array1)); }2、拷貝拷貝數(shù)組時也可以實現(xiàn)擴容1、Arrays中的copyOf方法public static void main(String[] args) { int[] array{1,2,3,4,5}; int[] newArrayArrays.copyOf(array,3); // 拷貝的數(shù)組新數(shù)組的長度 System.out.println(Arrays.toString(newArray)); }注意1、copyOf中的長度是從左往右進行計算的如上面拷貝的array只拷貝了前三個元素2、如果長度超過被拷貝的數(shù)組的個數(shù)其會自動在后邊補0實現(xiàn)了擴容的功能public static void main(String[] args) { int[] array{1,2,3,4,5}; int[] newArrayArrays.copyOf(array,8); // 拷貝的數(shù)組新數(shù)組的長度 System.out.println(Arrays.toString(newArray)); }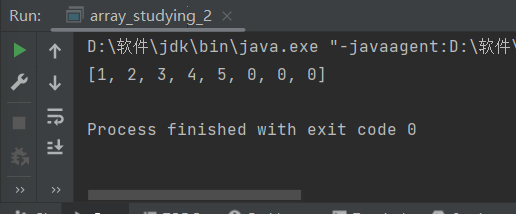2、Arrays中的copyOfRange方法1、起始和結束時的范圍是左開右閉的如下面的例子的下標范圍就是[2,4)public static void main(String[] args) { int[] array{1,2,3,4,5}; int[] newArrayArrays.copyOfRange(array,1,3); // 拷貝的數(shù)組 起始拷貝的下標結束拷貝的下標注下標范圍是[2,4) System.out.println(Arrays.toString(newArray)); }2、如果超過了原數(shù)組的范圍其會自動添0替代public static void main(String[] args) { int[] array{1,2,3,4,5}; int[] newArrayArrays.copyOfRange(array,4,8); // 拷貝的數(shù)組 起始拷貝的下標結束拷貝的下標注下標范圍是[4,8) System.out.println(Arrays.toString(newArray)); }3、System.arraycopy方法public static void main(String[] args) { int[] array{1,2,3,4,5}; int[] newArray new int[array.length]; System.arraycopy(array,2,newArray,1,2); // 拷貝的數(shù)組 起始拷貝下標拷貝到哪一個數(shù)組放在新數(shù)組的哪一個下標位置開始拷貝原數(shù)組的長度 System.out.println(Arrays.toString(newArray)); }注意1、System.arraycopy方法所包含的參數(shù)相對較多在使用時要先得知每一個參數(shù)的作用再使用2、System.arraycopy方法在使用時應當先創(chuàng)建一個新的數(shù)組才能將原數(shù)組拷貝到這個新的數(shù)組中去3、新數(shù)組沒有定義的內(nèi)容會自動補03、查找1、遍歷查找遍歷數(shù)組中的每一個元素進行查找向要的值優(yōu)點是邏輯簡單缺點是不夠效率public static int Find(int[] array1,int key){ for (int i 0; i array1.length; i) { if (array1[i]key) return i; } return -1; } public static void main(String[] args) { int[] array{1,2,3,4,5}; int key4; int nFind(array,key); if(n-1) System.out.println(key不在數(shù)組中); else System.out.println(key在數(shù)組中的下標為n); }2、二分查找二分查找只能在順序排序的數(shù)組中使用1、自定義實現(xiàn)二分查找自定義實現(xiàn)二分查找的關鍵在于判斷需要查找的值和順序排序的數(shù)組中的中間值的大小關系一次刷掉一半的值如此循環(huán)這個過程直到找出所需查找的值大大提升了代碼的效率public static int binarySearch(int[] array, int key){ int i0; int jarray.length-1; //循環(huán)判斷所需查找的值和數(shù)組中位數(shù)的大小關系 //一次篩選了一半的值 while(ij){ int mid(ij)/2; if(keyarray[mid]) imid1; else if (keyarray[mid]) jmid-1; else return mid; } return -1; } public static void main(String[] args) { int[] array{1,2,3,4,5}; int key4; int nbinarySearch(array,key); if (n-1) System.out.println(key不在數(shù)組中); else System.out.println(key在數(shù)組中的下標是n); }2、使用Arrays中的二分查找同時在Arrays中提供了實現(xiàn)二分查找的方法——binarySearch方法其實現(xiàn)的功能是在binarySearch方法中輸入兩個參數(shù)第一個參數(shù)指定在哪一個數(shù)組中進行查找第二個參數(shù)指定所需要查找的關鍵詞binarySearch方法會返回其在數(shù)組中對應的下標注意如果所需要查找的數(shù)在數(shù)組中不存在則返回的是-所需查找的數(shù)在數(shù)組中對應的排序位public static void main(String[] args) { int[] array{1,2,5,7,8}; int key5; int nArrays.binarySearch(array,key); // 要查找的數(shù)組元素的下標(注若該數(shù)不在數(shù)組中返回的是-(將key放入數(shù)組的排序位)) System.out.println(n); }4、排序1、自定義實現(xiàn)冒泡排序功能冒泡排序的核心在于每次比較數(shù)組中的兩個數(shù)的大小如果大于或小于則交換位置按照這樣的方法可以確定參與比較的數(shù)中的最大值或最小值按照這個方法可以依次確定數(shù)組中的第一大第二大第三大……從而實現(xiàn)排序的功能而這樣的方法相當于每次冒出了一個最大值或者最小值冒n-1次假設這個數(shù)組中有n個元素后這個數(shù)組就變得有序了public static void bubbleSort(int[] array){ for (int i 0; i array.length - 1; i) { //總共需要冒泡的次數(shù) boolean ntrue; //起始的n置為true for (int j 0; j array.length - 1 - i; j) { //單次冒泡時遍歷還沒有確定位置的數(shù)據(jù) if(array[j1]array[j]){ int temparray[j]; array[j]array[j1]; array[j1]temp; nfalse; //如果發(fā)生了任何一次交換則將n置為false } } if(ntrue) //如果n在某一次冒泡時沒有發(fā)生過一次交換數(shù)據(jù)說明剩下的數(shù)都已經(jīng)有序了 //此時就不需要再接著進行冒泡排序了 break; } } public static void main(String[] args) { int[] array{2,1,5,7,8}; bubbleSort(array); System.out.println(Arrays.toString(array)); }注意n-1次是一個數(shù)組中最多需要經(jīng)歷n-1次冒泡排序,而不是所有的數(shù)組都要經(jīng)歷n-1次冒泡排序當數(shù)組中剩下的數(shù)都已經(jīng)有序時此時就已經(jīng)沒有要再進行冒泡排序的必要了因此可以直接打破循環(huán)例如示例2、使用Arrays中的sort()方法實現(xiàn)排序注在Arrays也有實現(xiàn)排序的方法sort()方法其只需要一個參數(shù)——需要排序的數(shù)組sort()方法默認的是實現(xiàn)從小到大排序沒有返回值使用實例public static void main(String[] args) { int[] arraynew int[]{7,2,8,4,5}; Arrays.sort(array); //從小到大排序沒有返回值 System.out.println(Arrays.toString(array)); }3、實現(xiàn)逆序排序逆序排序就是將第一個元素放在最后第二個元素放在倒數(shù)第二以此類推實現(xiàn)逆序排序的方法使用的是“雙指針”的方法記錄最左邊和最右邊的數(shù)組下標并且交換最做左邊和最右邊的值再讓左邊的下標向右移動一位右邊的下標移動一位當兩個下標相等時或者左邊的下標大于右邊的下標時此時便實現(xiàn)了逆序排序//數(shù)組逆序?qū)⒌谝粋€元素放在最后第二個元素放在倒數(shù)第二以此類推 public static void reverse(int[] array){ int i0,jarray.length-1; while(ij){ int temparray[i]; array[i]array[j]; array[j]temp; i; j--; } } public static void main(String[] args) { int[] array{1,2,3,4,5}; reverse(array); System.out.println(Arrays.toString(array)); }說真的這兩年看著身邊一個個搞Java、C、前端、數(shù)據(jù)、架構的開始卷大模型挺唏噓的。大家最開始都是寫接口、搞Spring Boot、連數(shù)據(jù)庫、配Redis穩(wěn)穩(wěn)當當過日子。結果GPT、DeepSeek火了之后整條線上的人都開始有點慌了大家都在想“我是不是要學大模型不然這飯碗還能保多久”先給出最直接的答案一定要把現(xiàn)有的技術和大模型結合起來而不是拋棄你們現(xiàn)有技術掌握AI能力的Java工程師比純Java崗要吃香的多。即使現(xiàn)在裁員、降薪、團隊解散的比比皆是……但后續(xù)的趨勢一定是AI應用落地大模型方向才是實現(xiàn)職業(yè)升級、提升薪資待遇的絕佳機遇Java與大模型結合的技術優(yōu)勢推理環(huán)節(jié)的核心地位大模型訓練依賴Python生態(tài)的高性能計算資源而Java在推理階段模型部署、性能優(yōu)化、系統(tǒng)集成具有獨特優(yōu)勢。其“編寫一次處處運行”的特性使其能無縫集成到微服務、分布式系統(tǒng)等企業(yè)級架構中高效處理高并發(fā)請求。例如某電商平臺通過Java構建的大模型API網(wǎng)關支撐每日千萬級請求的穩(wěn)定運行響應時間縮短50%。生態(tài)成熟與性能穩(wěn)定Java擁有Spring Boot、Spring Cloud等成熟框架可快速實現(xiàn)服務注冊、負載均衡、熔斷降級等生產(chǎn)級能力。JVM的垃圾回收機制和即時編譯技術使其在長連接、高并發(fā)場景下表現(xiàn)優(yōu)于腳本語言。例如某金融系統(tǒng)采用Java實現(xiàn)大模型推理服務系統(tǒng)可用率長期保持99.99%以上。兼容性與工程化能力Java與現(xiàn)有業(yè)務系統(tǒng)的兼容性極強可降低大模型落地的集成成本。例如某制造企業(yè)通過Java將大模型與ERP系統(tǒng)對接實現(xiàn)生產(chǎn)流程的智能優(yōu)化故障率降低30%。同時Java在代碼規(guī)范、測試流程、版本管理等方面的積累能大幅降低大模型項目的研發(fā)成本和維護難度。因此捕獲AI掌握技術是關鍵讓AI成為我們最便利的工具.一定要把現(xiàn)有的技術和大模型結合起來而不是拋棄你們現(xiàn)有技術掌握AI能力的Java工程師比純Java崗要吃香的多。即使現(xiàn)在裁員、降薪、團隊解散的比比皆是……但后續(xù)的趨勢一定是AI應用落地大模型方向才是實現(xiàn)職業(yè)升級、提升薪資待遇的絕佳機遇如何學習AGI大模型作為一名熱心腸的互聯(lián)網(wǎng)老兵我決定把寶貴的AI知識分享給大家。 至于能學習到多少就看你的學習毅力和能力了 。我已將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰(zhàn)學習等錄播視頻免費分享出來。因篇幅有限僅展示部分資料需要點擊下方鏈接即可前往獲取2025最新版CSDN大禮包《AGI大模型學習資源包》免費分享**一、2025最新大模型學習路線一個明確的學習路線可以幫助新人了解從哪里開始按照什么順序?qū)W習以及需要掌握哪些知識點。大模型領域涉及的知識點非常廣泛沒有明確的學習路線可能會導致新人感到迷茫不知道應該專注于哪些內(nèi)容。我們把學習路線分成L1到L4四個階段一步步帶你從入門到進階從理論到實戰(zhàn)。L1級別:AI大模型時代的華麗登場L1階段我們會去了解大模型的基礎知識以及大模型在各個行業(yè)的應用和分析學習理解大模型的核心原理關鍵技術以及大模型應用場景通過理論原理結合多個項目實戰(zhàn)從提示工程基礎到提示工程進階掌握Prompt提示工程。L2級別AI大模型RAG應用開發(fā)工程L2階段是我們的AI大模型RAG應用開發(fā)工程我們會去學習RAG檢索增強生成包括Naive RAG、Advanced-RAG以及RAG性能評估還有GraphRAG在內(nèi)的多個RAG熱門項目的分析。L3級別大模型Agent應用架構進階實踐L3階段大模型Agent應用架構進階實現(xiàn)我們會去學習LangChain、 LIamaIndex框架也會學習到AutoGPT、 MetaGPT等多Agent系統(tǒng)打造我們自己的Agent智能體同時還可以學習到包括Coze、Dify在內(nèi)的可視化工具的使用。L4級別大模型微調(diào)與私有化部署L4階段大模型的微調(diào)和私有化部署我們會更加深入的探討Transformer架構學習大模型的微調(diào)技術利用DeepSpeed、Lamam Factory等工具快速進行模型微調(diào)并通過Ollama、vLLM等推理部署框架實現(xiàn)模型的快速部署。整個大模型學習路線L1主要是對大模型的理論基礎、生態(tài)以及提示詞他的一個學習掌握而L3 L4更多的是通過項目實戰(zhàn)來掌握大模型的應用開發(fā)針對以上大模型的學習路線我們也整理了對應的學習視頻教程和配套的學習資料。二、大模型經(jīng)典PDF書籍書籍和學習文檔資料是學習大模型過程中必不可少的我們精選了一系列深入探討大模型技術的書籍和學習文檔它們由領域內(nèi)的頂尖專家撰寫內(nèi)容全面、深入、詳盡為你學習大模型提供堅實的理論基礎。書籍含電子版PDF三、大模型視頻教程對于很多自學或者沒有基礎的同學來說書籍這些純文字類的學習教材會覺得比較晦澀難以理解因此我們提供了豐富的大模型視頻教程以動態(tài)、形象的方式展示技術概念幫助你更快、更輕松地掌握核心知識。四、大模型項目實戰(zhàn)學以致用當你的理論知識積累到一定程度就需要通過項目實戰(zhàn)在實際操作中檢驗和鞏固你所學到的知識同時為你找工作和職業(yè)發(fā)展打下堅實的基礎。五、大模型面試題面試不僅是技術的較量更需要充分的準備。在你已經(jīng)掌握了大模型技術之后就需要開始準備面試我們將提供精心整理的大模型面試題庫涵蓋當前面試中可能遇到的各種技術問題讓你在面試中游刃有余。因篇幅有限僅展示部分資料需要點擊下方鏈接即可前往獲取2025最新版CSDN大禮包《AGI大模型學習資源包》免費分享